Reinforcement learning
Reinforcement Learning
- Agents receive feedback from the environment in the form of rewards
- Utility of the agent is defined by the reward function
- Goal is to maximize expected future reward using only observations/interaction with the environment
- We still assume an MDP, but now we don’t know the true transition or reward function , and we have to actually try actions and make observations to learn them
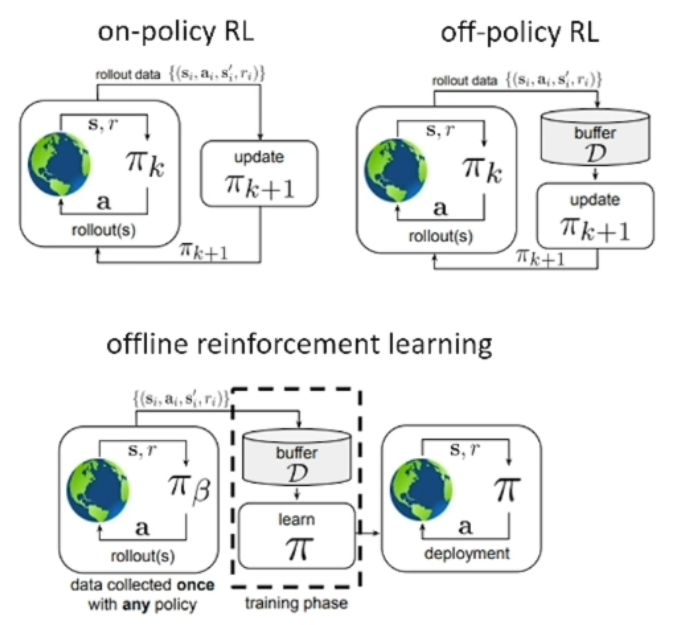
On-policy RL
On-policy learning is considered the more conventional approach to RL. In this setting we simply have our policy suggest actions that are taken by the agent, and the observed data is then used to update the policy. Here we are always staying “on policy” as we’re only ever learning along a trajectory suggested by the policy itself.
Off-policy RL
Off-policy learning describes the setting where a policy is able to learn from data collected by a number of policies. These methods still collect additional data as they go; for example, a policy could collect a number of observations, store them in a buffer, and learn from the entire buffer before advancing another step.
Offline RL
Offline learning takes place in the setting where our policy has no active interaction with the environment during the training phase. Instead, we have a dataset available a priori, collected by a typically unknown policy (e.g. could another RL policy, could be humans, etc), and our goal is to learn a policy strictly from this already available dataset alone.
Model-based Learning
- Model-based learning approaches RL by learning an approximate model of the environment using observations
- More specifically, we build an empirical MDP model, and then solve the learned MDP:
- Step 1: Learn empirical MDP
- Count outcomes for each ,
- Normalize to get estimate
- Keep track of experience rewards
- Step 2: Solve learned MDP
- Here we can use techiniques seen previously like value iteration
- Step 1: Learn empirical MDP
Model-free Learning
Passive Reinforcement Learning
- Given a fixed policy , we want to learn state values by following this policy passively. The agent has no choice regarding the actions that it takes, but it can still learn from the states in encounters.
- This is different from online planning, as we are actually taking actions in the real world
Direct Evaluation
- Goal is to compute state values under a given policy . When acting according to , each time a state is visited we compute and keep track of what the sum of discounted rewards turned out to be.
- Called direct evaluation for obvious reason, we are directly evaluating what the rewards are as we experience them
Tradeoffs
- Beneficial in that it’s easy to understand, doesn’t require prior knowledge of or , and eventually recovers the correct values
- Bad because it wastes information about state connections, and takes a long time to converge properly since each state must be learned separately
Sample-Based Policy Evaluation
- Policy evaluation enabled us to evaluate state values under a given fixed policy:
- To estimate this we can take samples of outcomes and average:
Temporal Difference Learning
- Here we update every time a transition is observed. Here the policy is still fixed.
- Sample of :
- Update to :
- This update process corresponds to an exponential moving average, which forgets about the past in preference for new information (old values were wrong anyway)
- TD learning is model-free way to do policy evaluation, but can’t easily turn value estimates into a policy. So learn q-values instead
Q-value Iteration
- Basic principle is that q-values are more useful, so use value iteration but compute q-values instead
- Start with , and compute depth q-values given
- Of course, we don’t have the real or functions, so we compute as we go. Known as Q-learning:
- Receive sample
- Compute new sample estimate
- Incorporate new estimate into running average:
- Q-learning converges to optimal policy even when acting suboptimally, known as off-policy learning
Q-learning: Recap
Want to perform Q-value updates to each Q-state
However this can’t be computed without knowing and , which we do not have in the typical online reinforcement learning scenario. So what do we know?
When a sample transition is observed, we have evidence which suggests that and . Thus, we have the approximation
As we observe more sample transitions, however, this approximation can be updated via a running average:
where is a some weighting parameter. The higher is, the more we accentuate recent sample transitions and thus learn faster, but at the detriment of stability.
Properties
Q-learning converges to the optimal policy, even when we start out acting suboptimally. This is what’s known as off-policy leaning. Note that this property assumes that you “explore enough,” and eventually make the learning rate sufficiently small.
Exploration vs Exploitation
Fundamental tradeoff of reinforcement learning: to follow the currently best known policy (exploitation), or try a new policy in hopes of coming across something even better (exploration)?
- Can explore using -greedy random actions: select with some small probability a random action, act according to current policy
- Lowering over time can reduce random bad actions after state space is sufficiently explored
Exploration Functions
- Help decide where to explore and for how long
- Exploration functions take value estimate and visit count and return an optimistic utility
Regret
- Regret is the measure of total mistake cost, the difference between expected rewards and the optimal expected rewards
- Minimizing regret is done by optimally learning to be optimal, minimizing the amount of mistakes along the fail
- For example, random exploration has higher regret than using exploration functions despite both ending up optimal
Generalizing Across States
- Realistically can’t keep table of all q-values, too many states
- Want instead to generalize from a few training states (fundamental ML concept)
- Can use feature-based representations, i.e. describe a state with a vector of features
Approximate Q-learning
- With a feature representation, can write a q, or value, function for any state with a few weights. Call these linear value functions:
- Q-learning with linear Q-functions
- Observe transition
- Difference equal to
- Exact Q’s:
- Approx Q’s:
- This approximate update comes from online least squares, where we find the gradient of the squared error w.r.t. our weight
Policy Search
- Often feature-based policies that work well don’t necessarily correspond to good esimates of values and q-values
- We want to learn policies that maximize rewards, not the values that predict them
- Simple policy search starts with initial linear value or Q-value function, make small changes to weights up and down and see if policy is better than before
Learning methods
Policy gradient
Goal is to learn a policy , a conditional distribution over the actions at time given state . represents the parameters of the model that represents the policy, and is typically taken as the weights of a neural network. So this neural network takes and outputs the conditional probability distribution .
The overall learning objective is here is to find the policy which maximizes the expected sum of discounted rewards over a given action horizon. That is,
We define to be this inner sum of discounted rewards under a policy
where on the right we’ve shown an approximate computation of one might make in practice after observing rollouts. The policy gradient method is then interested in computing the gradient of with respect to parameters , essentially giving us a way of changing the network parameters to yield the fastest increase in the value of . We can use this idea to iteratively improve our policy and maximize our expected sum of discounted rewards. This gives rise to the classic REINFORCE algorithm:
- Sample trajectory by running the policy
- Compute the gradient
- Perform simple gradient descent update